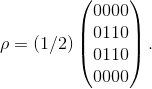Nota: vedi anche l'articolo "La disgiunzione di Gödel" di F. Beccuti.
Introduciamo quindi quella che è stata definita Macchina di Turing: in pratica questo termine indica uno qualsiasi degli attuali computer poiché essi sono realizzazioni fisiche di questa macchina ideale e universale in grado di eseguire qualsiasi algoritmo si possa formalizzare.
Come è noto si è dimostrata la perfetta equivalenza tra ogni sistema formale S e la macchina ideale di Turing: cioè è possibile programmare un computer che produca tutti e soli i teoremi di un dato sistema S e, viceversa, qualsiasi programmazione di un computer che produce formule, può essere rappresentata da un sistema formale S che derivi gli stessi risultati.
Quindi la scommessa dell'intelligenza artificiale è proprio quella di supporre che l'insieme delle capacità cognitive del nostro cervello, in particolare il processo del pensiero razionale, possa essere completamente riprodotto ed espresso da un programma evoluto per computer.
L'obiezione più nota a questo programma di ricerca è quella del filosofo Lucas nel celebre articolo "Menti, Macchine e Gödel" (del 1961):
"Data qualsiasi macchina che sia coerente e capace di fare semplice aritmetica, c'è una formula che essa è incapace di produrre come vera - cioè la formula è indimostrabile nel sistema - tuttavia noi la possiamo vedere come vera. Perciò nessuna macchina può essere un modello completo o adeguato della mente, le menti sono essenzialmente differenti dalle macchine"*.
Questa tesi segue proprio dall'argomento di incompletezza di Gödel, in particolare dal primo teorema (vedi il precedente post), ed è confermata dal Teorema di indefinibilità di Tarski (del 1936) che afferma che non è possibile definire la nozione di verità all'interno di un sistema formale.
Nota: si può definire la nozione di verità solo facendo una meta-analisi al di fuori del sistema, ad esempio usando la logica del secondo ordine.
Quindi sembrerebbe stabilita la tesi di Lucas secondo cui le nostre capacità cognitive, in particolare quelle che determinano il pensiero razionale, sono di certo superiori a quelle di una qualsiasi macchina o computer.
Tuttavia dobbiamo ricordare che il teorema di Gödel fa in effetti una affermazione che è del tutto condizionale:
"Se S è coerente allora G non è dimostrabile".
Ma la nostra mente è veramente in grado di riconoscere se un qualunque sistema formale è coerente dato che questa proprietà non può essere provata all'interno di un qualsiasi sistema?Nota: se S non è coerente si può dimostrare G (ma anche non-G) quindi la mente potrebbe essere un sistema incoerente e dimostrare che G è vera.
Inoltre ciò dovrebbe valere per qualsiasi sitema formale (come ad esempio sistemi più complessi che includono gli assiomi dell'infinito), perciò non è detto che la mente umana riesca sempre a riconoscere che un sistema è coerente.
Nota: la mente umana potrebbe essere un sistema coerente che non può dimostrare G (e quindi è incompleta) ma che non sa di essere coerente.
Lo stesso Gödel, che non era proprio un meccanicista, affermò nella Gibbs Lecture (del 1951), che potrebbe essere che "la mente umana (nel regno della matematica pura) [...] sia dunque equivalente ad una macchina finita che è incapace di comprendere interamente il suo funzionamento".
In definitiva, chi si occupa di intelligenza artificiale o di processi cognitivi e apprendimento, è costretto a fare una ben definita scelta o ipotesi di lavoro:
a) la mente umana non è riducibile ad una macchina di Turing che computa, quindi dobbiamo studiare le sue capacità cognitive in modo del tutto nuovo, poiché non possiamo trattarla come se fosse un oggetto computazionale**;
oppure
b) il nostro cervello funziona come un computer per quanto evoluto, tuttavia se la nostra mente è coerente, siamo costretti ad accettare che ci siano dei problemi irresolubili, come ad esempio dimostrare la sua coerenza***.
Nota: per approfondire l'interessante tema mente-cervello vedi l'ottimo articolo di Paul e Patricia Churchland "Il problema mente-cervello".
(*) Per completare il sistema S potremmo aggiungere G come assioma, si otterrebbe però un sistema S' in cui c'è una nuova formula G' indecidibile e così via, senza risolvere il problema.
(**) Qui il punto è proprio quello di voler attribuire alla mente un carattere diverso da quello computazionale (e non tanto la sua eventuale somiglianza ad un computer che è solo un modello interpretativo).
(***) Se la mente segue le leggi della fisica può senz'altro essere simulata computazionalmente; in questo contesto cervello e mente sono elementi complementari: la mente (software) è una funzione del cervello (hardware).
(Per chiarimenti su questo post vedi l'ottimo video di Francesco Berto)